![]()
Définition de PostgreSQL
PostgreSQL™ est un système de gestion de bases de données relationnelles objet (ORDBMS) fondé sur POSTGRES, Version 4.2™. Ce dernier a été développé à l'université de Californie au département des sciences informatiques de Berkeley. POSTGRES est à l'origine de nombreux concepts qui ne seront rendus disponibles au sein de systèmes de gestion de bases de données commerciaux que bien plus tard.
PostgreSQL™ est un descendant libre du code original de Berkeley. Il supporte une grande partie du standard SQL tout en offrant de nombreuses fonctionnalités modernes :
- requêtes complexes ;
- clés étrangères ;
- triggers ;
- vues modifiables ;
- intégrité transactionnelle ;
- contrôle des versions concurrentes (MVCC, acronyme de « MultiVersion Concurrency Control »).
De plus, PostgreSQL™ peut être étendu par l'utilisateur de multiples façons, en ajoutant, par exemple :
- de nouveaux types de données ;
- de nouvelles fonctions ;
- de nouveaux opérateurs ;
- de nouvelles fonctions d'agrégat ;
- de nouvelles méthodes d'indexage ;
- de nouveaux langages de procédure.
Et grâce à sa licence libérale, PostgreSQL™ peut être utilisé, modifié et distribué librement, quel que soit le but visé, qu'il soit privé, commercial ou académique.
Bref historique de PostgreSQL
Le système de bases de données relationnelles objet PostgreSQL™ est issu de POSTGRES™, programme écrit à l'université de Californie à Berkeley. Après plus d'une vingtaine d'années de développement, PostgreSQL™ annonce être devenu la base de données libre de référence.
Le projet POSTGRES à Berkeley
Le projet POSTGRES™, mené par le professeur Michael Stonebraker, était sponsorisé par le DARPA (acronyme de Defense Advanced Research Projects Agency), l'ARO (acronyme de Army Research Office), la NSF (acronyme de National Science Foundation) et ESL, Inc. Le développement de POSTGRES™ a débuté en 1986. Les concepts initiaux du système ont été présentés dans [ston86] et la définition du modèle de données initial apparut dans [rowe87]. Le système de règles fut décrit dans [ston87a], l'architecture du gestionnaire de stockage dans [ston87b].
Depuis, plusieurs versions majeures de POSTGRES™ ont vu le jour. La première « démo » devint opérationnelle en 1987 et fut présentée en 1988 lors de la conférence ACM-SIGMOD. La version 1, décrite dans [ston90a], fut livrée à quelques utilisateurs externes en juin 1989. Suite à la critique du premier mécanisme de règles ([ston89]), celui-ci fut réécrit ([ston90b]) pour la version 2, présentée en juin 1990. La version 3 apparut en 1991. Elle apporta le support de plusieurs gestionnaires de stockage, un exécuteur de requêtes amélioré et une réécriture du gestionnaire de règles. La plupart des versions qui suivirent, jusqu'à Postgres95™ (voir plus loin), portèrent sur la portabilité et la fiabilité.
POSTGRES™ fut utilisé dans plusieurs applications, en recherche et en production. On peut citer, par exemple : un système d'analyse de données financières, un programme de suivi des performances d'un moteur à réaction, une base de données de suivi d'astéroïdes, une base de données médicale et plusieurs systèmes d'informations géographiques. POSTGRES™ a aussi été utilisé comme support de formation dans plusieurs universités. Illustra Information Technologies (devenu Informix™, maintenant détenu par IBM) a repris le code et l'a commercialisé. Fin 1992, POSTGRES™ est devenu le gestionnaire de données principal du projet de calcul scientifique Sequoia 2000.
La taille de la communauté d'utilisateurs doubla quasiment au cours de l'année 1993. De manière évidente, la maintenance du prototype et le support prenaient un temps considérable, temps qui aurait dû être employé à la recherche en bases de données. Dans un souci de réduction du travail de support, le projet POSTGRES™ de Berkeley se termina officiellement avec la version 4.2.
Postgres95
En 1994, Andrew Yu et Jolly Chen ajoutèrent un interpréteur de langage SQL à POSTGRES™. Sous le nouveau nom de Postgres95™, le projet fut publié sur le Web comme descendant libre (OpenSource) du code source initial de POSTGRES™, version Berkeley.
Le code de Postgres95™ était écrit en pur C ANSI et réduit de 25%. De nombreux changements internes améliorèrent les performances et la maintenabilité. Les versions 1.0.x de Postgres95™ passèrent le Wisconsin Benchmark avec des performances meilleures de 30 à 50% par rapport à POSTGRES™, version 4.2. À part les correctifs de bogues, les principales améliorations furent les suivantes :
- le langage PostQUEL est remplacé par SQL (implanté sur le serveur). (La bibliothèque d'interface libpq a été nommée à partir du langage PostQUEL.) Les requêtes imbriquées n'ont pas été supportées avant PostgreSQL™ (voir plus loin), mais elles pouvaient être imitées dans Postgres95™ à l'aide de fonctions SQL utilisateur ; les agrégats furent reprogrammés, la clause GROUP BY ajoutée ;
- un nouveau programme, psql, qui utilise GNU Readline, permet l'exécution interactive de requêtes SQL ; c'est la fin du programme monitor ;
- une nouvelle bibliothèque cliente, libpgtcl, supporte les programmes écrits en Tcl ; un shell exemple, pgtclsh, fournit de nouvelles commandes Tcl pour interfacer des programmes Tcl avec Postgres95™ ;
- l'interface de gestion des « Large Objects » est réécrite ; jusque-là, le seul mécanisme de stockage de ces objets passait par le système de fichiers Inversion (« Inversion file system ») ; ce système est abandonné ;
- le système de règles d'instance est supprimé ; les règles sont toujours disponibles en tant que règles de réécriture ;
- un bref tutoriel présentant les possibilités du SQL ainsi que celles spécifiques à Postgres95™ est distribué avec les sources ;
- la version GNU de make est utilisée pour la construction à la place de la version BSD ; Postgres95™ peut également être compilé avec un GCC™ sans correctif (l'alignement des doubles est corrigé).
PostgreSQL
En 1996, le nom « Postgres95 » commence à mal vieillir. Le nom choisi, PostgreSQL™, souligne le lien entre POSTGRES™ et les versions suivantes qui intègrent le SQL. En parallèle, la version est numérotée 6.0 pour reprendre la numérotation du projet POSTGRES™ de Berkeley.
Beaucoup de personnes font référence à PostgreSQL™ par « Postgres » (il est rare que le nom soit écrit en capitales) par tradition ou parce que c'est plus simple à prononcer. Cet usage est accepté comme alias ou pseudo.
Lors du développement de Postgres95™, l'effort était axé sur l'identification et la compréhension des problèmes dans le code. Avec PostgreSQL™, l'accent est mis sur les nouvelles fonctionnalités, sans pour autant abandonner les autres domaines.
Les Binaires
Commande de base
pg_ctl :
- gestion de l'instance/cluster
- start/stop/kill
- init : Création autre espace de datas
- promote : promotion du standby
psql :
- client de connexion à un cluster
- précision utilisateur et/ou db
- passage de sql en cli ou script sql
pg_createcluster :
- Création d'un cluster (une instance Postgresql)
- Création des répertoires (/etc /var/lib)
pg_dropcluster :
- suppression d'un cluster
- cluster arrêté
pg_lscluster :
- Lister les cluster
pg_ctlcluster :
- Equivalent du pg_ctl
- contrôle du cluster (stop/start/… d'une instance)
Commande de sauvegarde
pg_dump :
- sauvegarde d'une instance
- différents formats : plain text, binaire…
- différents niveaux d'objets (cluster/db/table/schéma)
pg_dumpall :
- Sauvegarde intégrale en format binaire
pg_restore :
- restauration à partir d'une sauvegarde (pg_dumpall)
Système avancées
pg_controldata :
- Vérifie l'état du serveur et des infos critiques
pg_resetwal :
- En cas de crash avec problème de WAL (Write Ahead Logging)
- Attention : Datas inconsistentes (dernier recours)
pg_receive_wal :
- récupération des WAL d'une autre DB
pg_basebackup :
- récupération de datas par une connexion à une autre base de données (ec: Init réplication)
Gestion d'une instance PostgreSQL
Représentation schématique d'une instance
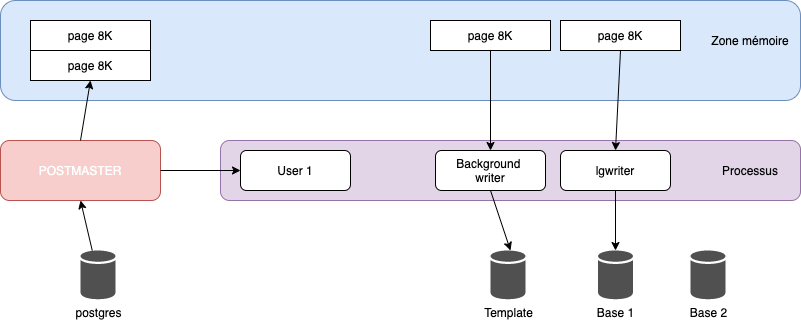
Les processus
L'outil permettant de lancer PostgreSQL s'appelle pg_ctl. Il est généralement appelé par le script de démarrage compris dans le répertoire /etc/init.d ou via le systemd, mais il est aussi exécutable manuellement.
Ce programme exécute un autre programme, appelé postgres. Il s'agit du processus père de tous les autres processus du serveur PostgreSQL. Très souvent, le nom postmaster est utilisé. Le programme existe même dans les paquets de PostgreSQL, mais il s'agit souvent que d'un lien symbolique vers l'exécutable postgres.
Regardons de plus prêt.
[root@pgsql01 ~]# ps -ef | grep [p]ostgres postgres 13435 1 0 20:14 ? 00:00:00 /usr/bin/postmaster -D /var/lib/pgsql/data postgres 13436 13435 0 20:14 ? 00:00:00 postgres: logger process postgres 13438 13435 0 20:14 ? 00:00:00 postgres: checkpointer process postgres 13439 13435 0 20:14 ? 00:00:00 postgres: writer process postgres 13440 13435 0 20:14 ? 00:00:00 postgres: wal writer process postgres 13441 13435 0 20:14 ? 00:00:00 postgres: autovacuum launcher process postgres 13442 13435 0 20:14 ? 00:00:00 postgres: stats collector process postgres 13443 13435 0 20:14 ? 00:00:00 postgres: bgworker: logical replication launcher
Important:
Les processus PostgreSQL
- Le processus postmaster
- logger process : Le processus de gestion des journaux applicatifs (optionnel)
- stats collector process : Le processus de collecte des statistiques (optionnel)
- writer process : Le processus d'écriture en tâche de fond
- wal writer process : Le processus d'écriture des journaux de transactions
- autovacuum launcher process : Le processus de maintenance des tables (optionnel)
- Le processus d'archivage (optionnel)
- Les processus de communication client/serveur</bootnote>
Postmaster process
Le premier processus est considéré comme le démon principal de PostgreSQL. Il est le père de tous les autres processus du serveur PostgreSQL. Son but principal est d'écouter toutes les connexions entrantes, soit par la socket soit par le port TCP/IP. Il est souvent dénommé postmaster.
Au démarrage, il charge la configuration, réalise tout un ensemble de tests, supprime des fichiers temporaires qui auraient été laissés dans le répertoire des données de PostgreSQL lors d'une précédente exécution, crée un fichier verrou dans le répertoire des données, alloue la mémoire partagée, initialise certains structures et ainsi de suite. S'il ne peut obtenir cette mémoire, le serveur complet s'arrête. Cela peut arriver par manque mémoire ou par une mauvaise configuration des paramètres système SHMALL et SHMMAX. Dans ce cas, le système d'exploitation refuse d'accorder la mémoire partagée demandée par postmaster.
Par contre, si l'allocation réussit, il va lancer les différents services nécessaire à PostgreSQL dans cet ordre :
- Logger process : le processus de gestion des journaux applicatifs (si activé) ;
- Stats collector : le processus de collecte des statistiques (si activé) ;
- Autovacuum launcher/worker : le processus de maintenance des tables (si activé) ;
- Bgwriter : le processus d'écriture en tâche de fond ;
- Wal writer : le processsus d'écriture des journaux de transactions en tâche de fond.
Quand une demande de connexion arrive, un processus fils est immédiatement créé. Ce dernier est responsable de l'identification et l'authentification du client et, si tout va bien, est chargé de la communication client/serveur.
Bien qu'allouer par lui, postmaster n'utilise pas la mémoire partagée. Cela le rend très robuste, et permet d'en faire le père de tous les processus, même dans les cas où il aurait été plus logique que le père soit un autre processus. En effet, en cas de crash des processus fils, il est capable de nettoyer le système en supprimant la mémoire partagée.
Bgwriter process
Pour améliorer l'interactivité, il a été décidé de créer un processus chargé des écritures. Ce processus, aussi appelé bgwriter pour background writer, va de temps à autre enregistrer les blocs modifiés du cache disque dans les fichiers de données. Cette action d'enregistrement est généralement déclenchée par un checkpoint.
Dans le meilleur des cas, toutes les écritures passeront par ce nouveau processus mais il faut savoir que les processus postgres peuvent toujours écrire si le processus d'écriture en tâche de fond n'arrive pas à tenir le rythme.
Le processus bgwriter est exécuté au lancement du serveur PostgreSQL et vit jusqu'à l'arrêt du serveur. Si ce processus meurt de façon inattendue, le processus postmaster traite cet événement comme la mort inattendue d'un processus postgres : arrêt du serveur PostgreSQL en urgence. Au prochain démarrage, une procédure de restauration aura lieu. Quelques variables permettent de configurer le moment de l'exécution d'un checkpoint :
checkpoint_timeout indique la durée maximale sans CHECKPOINT ; checkpoint_segments indique le nombre maximum de journaux de transactions utilisés sans CHECKPOINT.
Wal writer process
Le “wal writer process” est apparu en 8.3 pour gérer la même activité d'écriture en tâche de fond, mais cette fois du côté des journaux de transactions. Le but est toujours de décharger les processus postgres de ce travail. Il enregistre les modifications dans les journaux de transactions au moment du COMMIT ou si les informations à enregistrer ne tiennent plus dans le cache. Ce cache spécifique aux journaux de transactions permet d'éviter les écritures tant que le COMMIT n'est pas reçu. Cependant, comme tout cache, il a une limite paramétré avec la variable wal_buffers. En cas de débordement du cache, le “wal writer process” écrit les données sur disque.
De plus, dans le cas où l'enregistrement asynchrone est activé (paramètre asynchronous_commit), il garantit que l'enregistrement se fait au plus tard au bout de trois fois le délai indiqué par le paramètre wal_writer_delay.
Stats collector process
Ce processus est activé par défaut en 8.3. Contrairement aux deux précédents types de processus, il peut être désactivé grâce au paramètre track_activities.
Le but de ce processus est de récupérer certaines informations des processus postgres. Il s'agit des statistiques sur le nombre de lignes lues, insérées, modifiées et supprimées. Ce sont aussi des statistiques sur le nombre de blocs disque lus ou écrits. Bref, toutes sortes d'informations sur l'activité du serveur sont comptés à condition que le paramètre track_count soit activé.
Ces informations sont récupérées via un port UDP configuré en mode non bloquant, ce qui permet, en cas de retard du collecteur, que les messages soient ignorés et ne ralentissent pas le serveur PostgreSQL. Aucun processus postgres ne doit être ralenti, et encore pire bloqué, par l'envoi des informations de statistique. Mais du coup, cela sous-entend que les statistiques ne sont pas forcément exactes.
Les données sont temporairement enregistrées dans le fichier global/pgstat.tmp. On y trouve les statistiques du processus d'écriture en tâche de fond, mais aussi des statistiques sur les bases et relations. Une fois l'enregistrement terminé, le fichier est renommé en global/pgstat.stat. Le fichier est d'autant plus gros que le nombre de bases et relations est important. Le fichier peut devenir très gros si un grand nombre de tables temporaires est créé. Cela génère une activité non négligeable étant donné que le fichier est écrit à chaque travail du collecteur de statistiques, c'est-à-dire toutes les 500 ms.
<bootnote>Une solution à ce problème sera proposée en 8.4. Le fichier pgstat.stat sera créé dans un répertoire qui pourra être placé dans un disque RAM. Ce répertoire sera personnalisable via un paramètre du fichier de configuration postgresql.conf. Il sera copié dans le répertoire global à l'arrêt du serveur et récupéré à cet endroit au prochain démarrage.
Les processus postgres font appel au collecteur pour fournir les informations sur les tables accédées, lues, etc. L'opération VACUUM fait de même pour indiquer les bases de données et les relations supprimées. Dans le cas des bases, l'ordre DROP DATABASE envoie déjà ce message au collecteur, mais ce n'est malheureusement pas le cas avec un DROP TABLE. Cela explique que, en l'absence de VACUUM et si la base utilise beaucoup de tables temporaires, ces dernières sont toujours présentes dans le fichier pgstat.stat, sans aucune raison.
Ce processus est exécuté au lancement du serveur PostgreSQL et vit jusqu'à l'arrêt du serveur. Si ce processus meurt de façon inattendue, le processus postmaster tente de le relancer plusieurs fois si nécessaire.
Question mémoire, il n'utilise pas la mémoire partagée mais comprend quelques structures qu'il conserve tout au long de son exécution. La taille de ces structures dépend directement du nombre de processus car une structure est alloué par processus. Pour donner une idée de la quantité de mémoire impliquée, cela représente environ 128 Ko de mémoire partagée allouée jusqu'à cent processus.
Autovacuum launcher/worker
Ce démon a pour but de procéder au nettoyage des tables si elles ont eu une activité suffisante pour nécessiter cette opération.
Depuis la version 8.3, il existe le démon principal, dénommé autovacuum launcher, et des processus secondaires, appelés autovacuum worker.
L'autovacuum launcher est exécuté dès le démarrage par le processus postmaster. Son exécution durera jusqu'à l'arrêt complet du serveur PostgreSQL. Si ce processus meurt de façon inattendue, le processus postmaster tente de le relancer plusieurs fois si nécessaire. Au démarrage, il commence par allouer un petit espace de mémoire partagée entre tous les processus autovacuum. Cet espace mémoire est vraiment restreint en utilisation aux processus autovacuum et a une taille très limitée (144 octets sur un serveur tout juste installé). Cette taille dépend du paramètre autovacuum_max_workers.
L'allocation mémoire réalisée, il s'endort. Il se réveille à intervalle régulier dépendant du paramètre autovacuum_naptime. Lors de ce réveil, il indique la base de données à traiter dans l'espace en mémoire partagée qu'il a alloué à son lancement et demande au processus postmaster d'exécuter un processus autovacuum worker. Il ne peut exécuter lui-même un autovacuum_worker car il est moins robuste que le processus postmaster, notamment parce qu'il utilise la mémoire partagée où peut survenir une corruption.
Lorsqu'un nouveau processus autovacuum est exécuté, il détecte la présence de la mémoire partagée liée aux processus autovacuum et comprend du coup qu'il est un autovacuum worker. Il se connecte à la base de données indiquée dans la mémoire partagée, recherche les tables et index à traiter, les traite puis quitte en envoyant un signal SIGUSR1 au processus autovacuum launcher.
Ainsi, il prévient ce processus pour que ce dernier puisse demander l'exécution d'un nouvel autovacuum worker (utile quand on a atteint le maximum de processus de ce type et qu'on est malgré tout en attente pour en exécuter un autre).
Plusieurs autovacuum worker peuvent fonctionner en même temps, avec un maximum dépendant du paramètre autovacuum_max_workers. Plusieurs peuvent travailler en même temps sur la même base. Ils ne se bloqueront pas sur la même table ou sur le même index car ils indiquent en mémoire partagée la table (ou l'index) sur lesquels ils travaillent. Les coûts associés à l'autovacuum sont balancés entre chaque autovacuum worker (voir pour cela les paramètres autovacuum_vacuum_cost_delay et autovacuum_vacuum_cost_limit). Lorsqu'un autovacuum worker exécute réellement un VACUUM, une mémoire supplémentaire est allouée, dont la taille dépend du paramètre maintenance_work_mem.
Des traces sont disponibles pour ce processus. Le paramètre log_autovacuum_min_duration permet d'enclencher des traces pour tous les processus autovacuum dont la durée d'exécution dépasse la durée indiquée par le paramètre. Des traces supplémentaires sont disponibles au niveau DEBUG1 (une trace indiquant la base de donnée traitée par un autovacuum worker), au niveau DEBUG2 (pour comprendre le calcul des coûts associés au VACUUM) et au niveau DEBUG3 (indiquant le résultat des opérations VACUUM et ANALYZE).
Archiver process
Désactivé par défaut, ce processus a pour but de gérer l'archivage des journaux de transactions.
L'activation se fait de façon simple : il suffit de configurer archive_mode à on. Ceci fait, après un redémarrage de PostgreSQL, un processus nommé archiver process apparaît. Il n'a pas de consommation mémoire importante et il n'utilise pas non plus la mémoire partagée. Il sera là jusqu'à l'arrêt du serveur PostgreSQL. Si jamais il meurt de façon inattendue, le serveur tentera plusieurs fois de le relancer. Il communique avec les autres processus au moyen de signaux. SIGHUP par exemple lui fait recharger la configuration.
S'il reçoit le signal SIGUSR1 ou au plus tard au bout de 60 secondes, il lit le contenu du répertoire pg_xlog/archive_status. Il récupère le fichier d'extension .ready le plus ancien, en déduit le nom du journal de transactions à archiver et exécute la commande d'archivage. Si cette dernière renvoie le code de statut 0 (signifiant la réussite de l'opération), il renomme le fichier .ready en .done et se rendort.
Le nom du processus affiché par ps dépend essentiellement de son état :
- “archiver process” au départ ;
- “archiving %s”, lors de l'archivage du journal de transactions %s ;
- “failed on %s” si l'archivage a échoué pour le journal %s ;
- “last was %s” dès qu'un journal de transactions a été archivé avec succès.
En dehors du nom du processus, il est possible de détailler l'exécution de ce processus. Le niveau de traces DEBUG3 indique le nom de la commande d'archivage en cours d'exécution alors que le niveau DEBUG1 signale un journal de transactions archivé avec succès.
Logger process
Disponible depuis la version 8.0 mais désactivé par défaut, ce processus sert à rediriger les messages de la sortie standard vers les journaux applicatifs gérés par PostgreSQL. Il apparaît sous le nom de “ logger process”. Il utilise très peu de mémoire et se détache en plus de la mémoire partagée. La communication avec les autres processus se fait par l'intermédiaire d'un tube.
Il réagit notamment à deux signaux : SIGHUP pour lui demander de relire la configuration et SIGUSR1 pour demander une rotation du journal applicatif.
Dans le cas du SIGHUP, le journal est changé si le répertoire des journaux applicatifs ou le modèle de nom des journaux a changé.
Ce processus est exécuté au lancement du serveur PostgreSQL et vit jusqu'à l'arrêt du serveur. Si ce processus meurt de façon inattendue, le processus postmaster tente de le relancer plusieurs fois si nécessaire.
Processus communication client/serveur
Ce sont les plus nombreux. Chaque processus postgres s'occupe de la communication entre le client qui s'est connecté et le serveur, que ce client soit l'outil psql, l'outil de sauvegarde pg_dump ou n'importe quel autre application capable de se connecter à une base de données PostgreSQL. Cependant, il n'y en aura jamais plus de max_connections.
Ils utilisent principalement la mémoire partagée pour stocker les pages des tables et index qu'ils utilisent. Ils utilisent aussi une partie de mémoire qui leur est propre, par exemple pour les tris ou pour les créations d'index.
Lorsqu'un client se connecte, le premier travail du processus postgres est de s'assurer de l'identité du client. Ceci fait, il effectue si nécessaire son authentification. Ensuite, il est en attente des requêtes du client. À réception d'une requête, il procède à son analyse et à son exécution. Pour cela, il peut avoir besoin de lire des tables qu'il placera dans la mémoire partagée. Une fois le résultat obtenu, il envoie le résultat au client. Il envoie les traces au collecteur de traces, récupère les statistiques qu'il fournir au collecteur de statistiques.
Annexe
https://docs.postgresql.fr/12/user-manag.html
https://docs.postgresql.fr/12/kernel-resources.html
https://computingforgeeks.com/how-to-install-pgadmin-4-on-centos-linux/
https://www.tecmint.com/install-postgresql-on-ubuntu/
https://www.2ndquadrant.com/fr/resources/highly-available-postgresql-clusters/
https://www.digora.com/fr/blog/postgresql-episode-2-architecture
https://www.tecmint.com/install-postgresql-and-pgadmin-in-rhel-8/
https://www.tecmint.com/configure-postgresql-streaming-replication-in-centos-8/
https://www.msi.nc/basedeconnaissance/voir-comprendre-processus-cours-postgresql/