Table des matières
Qu'est-ce que Hortonworks HDF ?
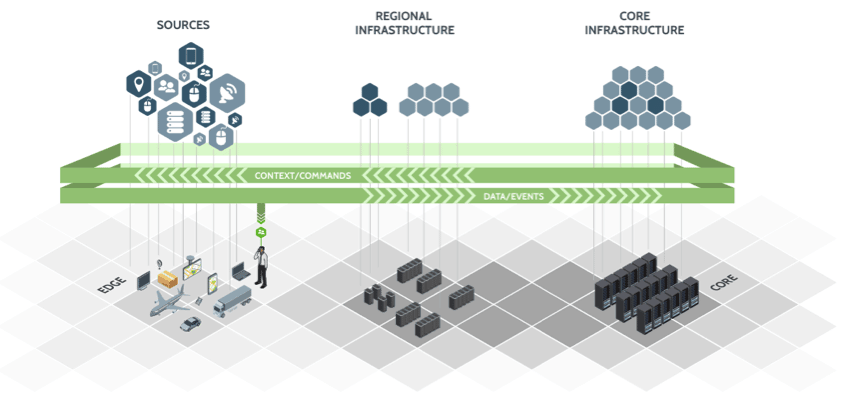
Hortonworks DataFlow (HDF) est une plateforme d'analytique évolutive et en temps réel qui ingère, organise et analyse des données afin d'obtenir des informations vitales et immédiatement exploitables. DataFlow répond aux principaux défis auxquels les entreprises font face en matière de data-in-motion : traitement de trains de données en temps réel et à grande échelle, provenance et ingestion de données depuis des appareils connectés, applications en périphérie et sources de transmission en continu.
La solution HDF permet d'avoir une approche sans code qui permet de créer facilement des pipelines de données complexes. Elle propose une interface simple d'utilisation et extrêmement visuelle. Elle utilise la technologie Apache NiFi, qui permet d'intégrer des données provenant d'un large éventail de sources. Il est alors possible de recueillir un grand nombre de données. Les informations s'obtiennent en temps réel et permettent de réagir au plus tôt.
Des délais de développement court pour l'intégration de vos données
La solution possède une approche sans code, permettant de créer facilement des pipelines de données complexes. HDF offre une interface utilisateur simple et visuelle, qui permet de créer des flux de données sophistiqués pour ingérer, transformer et enrichir des données, depuis toutes sortes de sources de transmission en continu. Utilisant la technologie Apache NiFi, HDF peut ingérer des données provenant d'un large éventail de sources : appareils, applications d'entreprise, systèmes de partenaire ou applications en périphérie générant des données transmises en continu et en temps réel. Cela offre de nombreux avantages comme la réduction des délais de développement pour l'intégration des données.
Gérez et sécurisez vos données de la périphérie à l'entreprise
HDF permet de recueillir de grands volumes de données « at the edge », y compris depuis des périphériques utilisant la technologie Minifi. il est désormais possible de configurer des modèles de déploiement IoT largement distribués pour recueillir facilement des données régionales à l'aide de la technologie Minifi, afin de diffuser des données en continu depuis la périphérie. Une intégration avec Apache Ranger offre à HDF l'avantage d'une sécurité transparente à travers toutes vos données, qu'elles soient en mouvement ou au repos.
Hortonworks data flow cherche à obtenir des informations en temps réel afin de réagir plus rapidement que jamais. L'obtention d'informations en temps réel permet de réagir plus tôt. Utilisant la puissante plateforme de streaming Apache Kafka, HDF peut traiter plusieurs millions de transactions par seconde, identifier des modèles clés, effectuer des comparaisons avec des modèles de machine learning et offrir des analyses prédictives et prescriptives afin d'aider les dirigeants d'entreprise à prendre des décisions éclairées et à saisir des opportunités. Streaming Analytics Manager offre un outil visuel pour créer des applications complexes de streaming, permettant ainsi aux analystes de données et aux data scientists d'obtenir des informations essentielles et exploitables à partir de données en temps réel.
Création d'une architecture de données qui s'adapte à l'évolution de l'IoT
HDF est une technologie 100 % open source. Vous pouvez ainsi concevoir une architecture à l'épreuve du temps, sans dépendre d'un fournisseur. Cette solution constitue une technologie éprouvée, choisie par des centaines de clients pour son efficacité dans des cas d'utilisation vitaux. Les clients peuvent implémenter des solutions IoT pour des secteurs comme l'automobile, la fabrication, le transport, les services publics, le commerce au détail et le secteur public. Vous pouvez adopter une stratégie vous permettant de gérer des données volumineuses et diversifiées à très grande vitesse.
HDF est le seul produit du secteur à proposer des fonctions clés en main de provenance des données et de gouvernance des données de la périphérie à l'entreprise. À l'ère du RGPD et autres réglementations en matière de conformité, il est essentiel de pouvoir tracer les données, y compris quand elles sont transmises en continu. Dans HDF, NiFi permet de suivre la provenance des données, sans qu'aucune configuration ou installation supplémentaire ne soit nécessaire. En intégrant Apache Atlas, vous bénéficiez d'une gouvernance complète de vos données, de la périphérie à l'entreprise.
Cluster Types HDF et Recommandations
| Type de cluster | Description | Nombre de VM ou de noeuds | Spécification du noeud | Réseau |
|---|---|---|---|---|
| Sandbox VM HDF unique | Evaluez HDF sur une machine locale. Il n'est pas recommandé de déployer autre chose que des applications simples. | 1 VM | Au moins 4 Go de RAM | |
| Cluster d'évaluation | Evaluez HDF dans un environnement en cluster. Utilisé pour évaluer HDF pour des flux de données simples et des applications de streaming. | 3 VM ou Noeuds | 16 Go de RAM 8 coeurs ou vCoeurs | |
| Petit cluster de développement | Utilisez ce cluster dans les environnements de développement. | 6 VMs ou Noeuds | 16 Go de RAM 8 coeurs ou vCoeurs | |
| Cluster QE moyen | Utilisez ce cluster dans les environnements QE. | 8 VMs ou Noeuds | 32 Go de RAM 8 à 16 coeurs ou vCoeurs | |
| Petit cluster de production | Utilisez ce cluster dans de petits environnements de production. | 15 VMs ou Noeuds | 64 à 128 Go de RAM 8 à 16 coeurs ou vCoeurs | Carte réseau 1 Go en Bond |
| Cluster de production moyenne | Utilisez ce cluster dans un environnement de production moyen. | 24 VMs ou Noeuds | 64 à 128 Go de RAM 8 à 16 coeurs ou vCoeurs | Carte réseau 10 Go en Bond |
| Grand cluster de production | Utilisez ce cluster dans un grand environnement de production. | 32 VMs ou Noeuds | 64 à 128 Go de RAM 16 coeurs ou vCoeurs | Carte réseau 10 Go en Bond |
Recommandations matériel
Recommandations pour Kafka
- Noeud Broker Kafka: huit coeurs, 64 Go à 128 Go de RAM, deux ou plus de disques de 8To SAS/SSD, et une carte réseau de 10Gbe.
- Minimum de trois noeuds Broker Kafka
- Profil matériel: Plus de RAM et des disques à vitesse plus rapide sont meilleurs; La carte réseau 10 GbE est idéale.
- 75 Mo par seconde et par nœud est une estimation prudente. Vous pouvez aller beaucoup plus haut si plus de RAM et une latence réduite entre l'écriture/la lecture et donc une carte réseau de 10 Go sont nécessaires.
Avec un minimum de 3 noeuds dans votre cluster, vous pouvez vous attendre à un transfert de données de 225 Mo/s.
Vous pouvez effectuer un dimensionnement supplémentaire en utilisant la formule suivante: nombre_de_brokers = debit_souhaite (Mo/sec)/75
Exemple pour 1Go/s:
14 = 13,65 = 1024 / 75
Il faudra donc 14 noeuds pour avoir un débit de 1Go/s.
Recommandations pour Storm
- Noeud de traitement Storm: 8 coeur, 64 Go de RAM, Carte réseau 1 GbE
- Minimum de 3 Noeud de traitement Storm
- Noeud Nimbus: Minimum de 2 noeud Nimbus, 4 coeur, 8 Go de RAM
- Profil matériel: les E/S disque ne sont pas si important; il vaut mieux avoir plus de coeurs.
- 50 Mo par seconde par noeud avec une lecture de topologie de complexité faible à moyenne à partir de Kafka et aucune recherche externe. Les topologies de complexité moyenne et élevée peuvent réduire le débit.
Avec un minimum de 2 nimbus, 2 cluster de travail, vous pouvez vous attendre à exécuter 100 Mo/s de topologie de complexité faible à moyenne.
Un dimensionnement supplémentaire peut être effectué comme suit. Formule: nombre_de_brokers = debit_souhaite (Mo/sec)/50
Exemple pour 1Go/s:
21 = 20,48 = 1024 / 50
Il faudra donc 21 noeuds de traitement pour avoir un débit de 1Go/s.
Recommandations pour NiFi
NiFi est conçu pour tirer parti de:
- tous les coeurs d'une machine
- toute la capacité du réseau
- toute la vitesse du disque
- plusieurs gigaoctets de RAM (mais généralement pas tous) sur un système
Par conséquent, il est important que NiFi fonctionne sur des noeuds dédiés.
Voici les spécifications de serveur et de dimensionnement recommandées pour NiFi:
- Minimum de 3 noeuds
- 8+ coeurs par noeud (plus c'est mieux)
- 6+ disques par noeud (SSD ou rotatif)
- Au moins 8 Go de RAM
| Si vous voulez ce débit soutenu … | Alors, il faut au minimum fournir ce matériel … |
|---|---|
| 50 Mo et des milliers d'événements par seconde | * 1 ou 2 noeud * 8 ou plus de coeurs par noeud, bien que plus c'est mieux * 6 disques ou plus par noeud (SSD ou rotatif) * 2 Go de mémoire par noeud * Cartes réseau de 1 Go (bond) |
| 100 Mo et des dizaines de milliers d'événements par seconde | * 3 ou 4 noeuds * 16 ou plus de coeurs par noeud, bien que plus c'est mieux * 6 disques ou plus par noeud (SSD ou rotatif) * 2 Go de mémoire par noeud * Cartes réseau de 1 Go (bond) |
| 200 Mo et des centaines de milliers d'événements par seconde | * 5 à 7 noeuds * 24 ou plus de coeurs par noeud (processeurs efficaces) * 12 disques ou plus par noeud (SSD ou rotatif) * 4 Go de mémoire par noeud * Cartes réseau de 10 Go (bond) |
| 400 à 500 Mo/s et des centaines de milliers d'événements par seconde | * 7 - 10 noeuds * 24 ou plus de coeurs par noeud (processeurs efficaces) * 12 disques ou plus par noeud (SSD ou rotatif) * 6 Go de mémoire par noeud * Cartes réseau de 10 Go (bond) |
Descriptions des services
Vous trouverez ci-dessous une présentation succinctes de tous les services présent dans la distribution HDF.
- Zookeeper
- Ambari Metrics
- Smartsense
- Ambari Infra Solr
- Kafka
- Schema Registry
- Knox
- Logsearch
- NiFi
- NiFi-Registry
- Ranger
- Storm
- Streaming Analytics Manager (SAM)
Zookeeper
Apache ZooKeeper est un système open-source de synchronisation et de coordination des systèmes distribués.
ZooKeeper permet de maintenir des informations de configuration. Il propose aussi des services synchronisés et des services de groupe pour une large variété d’applications distribuées.
ZooKeeper facilite la synchronisation entre les process en maintenant un statut sur les serveurs ZooKeeper qui stocke l’information sur des fichiers de log locaux. Chaque machine client communique avec l’un des serveurs pour retrouve l’information.
ZooKeeper présente plusieurs avantages. Il se distingue tout d’abord par sa simplicité, puisque la coordination est aidée par un espace de noms partagé. Il s’agit par ailleurs d’une technologie très fiable, puisque le système continue à fonctionner même si l’un des noeuds tombe en panne.
Ambari metrics
Ambari Metrics System (AMS) collecte, agrège et sert les métriques Hadoop et système dans les clusters gérés par Ambari.
AMS comprend quatre composants:
- Les moniteurs de métriques sur chaque hôte du cluster collectent des métriques au niveau du système et les publient dans le collecteur de métriques.
- Les récepteurs Hadoop se connectent aux composants Hadoop pour publier des métriques Hadoop dans le collecteur de métriques.
- Le Metrics Collector est un démon qui s'exécute sur un hôte spécifique du cluster et reçoit les données des éditeurs enregistrés, des moniteurs et des récepteurs.
- Grafana est un démon qui s'exécute sur un hôte spécifique dans le cluster et sert des tableaux de bord prédéfinis pour visualiser les métriques collectées dans le collecteur de métriques.
Le diagramme suivant montre comment les composants d'AMS fonctionnent ensemble pour collecter des métriques et mettre ces métriques à la disposition d'Ambari:

Smartsense
Hortonworks SmartSense Tool (HST) donne à tous les clients abonnés au support un accès à un service unique qui analyse les données de diagnostic du cluster, identifie les problèmes potentiels et recommande des solutions et des actions spécifiques. Ces analyses identifient de manière proactive les problèmes invisibles et informent les clients des problèmes potentiels avant qu'ils ne surviennent.
SmartSense fournit des capacités de collecte de données de diagnostic de cluster, permettant aux clients de collecter rapidement la configuration, les métriques et les journaux qu'ils peuvent utiliser pour analyser et dépanner les cas de support.
Infra Solr
De nombreux services dans HDP/HDF dépendent des services de base pour indexer les données. Par exemple, Apache Atlas utilise des services d'indexation pour baliser la recherche de texte sans lignage, et Apache Ranger utilise l'indexation pour les données d'audit. Le rôle d'Ambari Infra est de fournir ces services partagés communs pour les composants de pile.
Actuellement, le service Ambari Infra ne comporte qu'un seul composant: l'instance Infra Solr.
L'instance Infra Solr est une installation Apache Solr entièrement gérée. Par défaut, une installation SolrCloud à noeud unique est déployée lorsque le service Ambari Infra est choisi pour l'installation; cependant, vous devez installer plusieurs instances Infra Solr afin de distribuer l'indexation et de rechercher Atlas, Ranger et LogSearch (Techpreview).
Pour installer plusieurs instances Infra Solr, il vous suffit de les ajouter aux hôtes de cluster existants via la fonction + Ajouter un service d’Ambari. Le nombre d'instances Infra Solr que vous déployez dépend du nombre de noeuds dans le cluster et des services déployés.
Étant donné qu'une instance Ambari Infra Solr est utilisée par plusieurs composants HDP/HDF, vous devez être prudent lors du redémarrage du service, afin d'éviter de perturber ces services dépendants. Dans HDP 2.5 et versions ultérieures, Atlas, Ranger et Log Search (Techpreview) dépendent du service Ambari Infra.
Note:
L'instance Infra Solr est destinée à être utilisée uniquement par les composants HDP/HDF; l'utilisation par des composants ou des applications tiers n'est pas prise en charge.
Kafka
Apache Kafka est une plateforme de streaming distribuée gérée par la fondation Apache.
Apache Kafka était un système de messagerie distribué. Initialement développé par l’équipe de Jay Kreps chez LinkedIn, et plus tard publié, en 2011, en tant que projet open-source Apache. Kafka est un service réputé rapide, scalable, partionné et répliqué.
Au fil du temps, cet outil a beaucoup évolué. Il s’agit aujourd’hui d’une plateforme centralisée pour le stockage et l’échange en temps réel de toutes les données émises par les entreprises qui l’utilisent. De nombreuses firmes l’ont adopté, à tel point que Kafka est aujourd’hui considéré comme une plateforme standard pour les pipelines de traitement de données.
Kafka possède les caractéristiques principales suivantes :
- Scalabilité : Il a été conçu en tant que système distribué facile à monter en charge, sans arrêt de production.
- Performance : Il offre un haut niveau de performances I/O, que ce soit pour la publication de messages ou leur abonnement (plusieurs millions de lectures/écritures par seconde).
- Durabilité : Il permet de persister des messages sur disque, aidant ainsi à leur consommation en mode batch (comme dans un contexte ETL), en addition des opérations temps-réel.
- Fiabilité : Il permet de répliquer des messages, de supporter des abonnements multiples et de rééquilibrer automatiquement les consommateurs en cas de panne.
Schema Registry
La plate-forme Hortonworks DataFlow (HDF) fournit des services de gestion de flux, de traitement de flux et d'entreprise pour la collecte, la conservation, l'analyse et la gestion des données en mouvement dans les centres de données sur site et les environnements cloud.
Comme le montre le diagramme ci-dessous, Hortonworks Schema Registry fait partie des services d'entreprise qui alimentent la plate-forme HDF.

Schema Registry fournit un référentiel partagé de schémas qui permet aux applications et aux composants HDF (NiFi, Storm, Kafka, Streaming Analytics Manager, etc.) d'interagir de manière flexible les uns avec les autres.
Les applications créées à l'aide de HDF ont souvent besoin d'un moyen de partager des métadonnées à travers 3 dimensions:
- Format des données
- Schéma
- Sémantique ou signification des données
Le principe de conception du registre de schémas est de fournir un moyen de relever les défis de la gestion et du partage de schémas entre les composants de HDF et de telle manière que les schémas soient conçus pour prendre en charge l'évolution de sorte qu'un consommateur et un producteur puissent comprendre différentes versions de ces schémas. mais toujours lire toutes les informations partagées entre les deux versions et ignorer en toute sécurité le reste.
Par conséquent, la valeur fournie par Schema Registry pour HDF et les applications qui s'y intègrent sont les suivantes:
- Registre centralisé - Fournis un schéma réutilisable pour éviter d'attacher un schéma à chaque élément de données
- Gestion des versions - Définis la relation entre les versions de schéma afin que les consommateurs et les producteurs puissent évoluer à des rythmes différents
- Validation du schéma - Active la conversion de format générique, le routage générique et la qualité des données
Utilisation du registre de schémas dans la gestion des flux:

Knox
Apache Knox est l’API Gateway de la fondation Apache. Créé en 2013, il vise à répondre à des besoins de sécurité des clusters Hadoop.
Une API (Application Programming Interface) Gateway est une application qui permet d’avoir accès à un groupe de services via une entrée unique.
Concrètement, dans le cas de Knox, elle permet aux applications extérieures et aux clusters d’avoir accès aux différents frameworks de Hadoop (Hive, Map Reduce, HDFS, etc.) et de les utiliser via un seul canal.
L’initiateur de la requête va dans un premier temps envoyer la requête à Knox qui va interroger le service d’autorisation et/ou d’authentification (tel que Kerberos, Shiro, LDAP, etc.) afin de savoir si cet utilisateur a le droit de contacter le service concerné. Ensuite, Knox va aller interroger un service Hadoop, et retourner la réponse à l’utilisateur.
Cela permet donc de :
- Protéger les informations du cluster de l'extérieur car on ne s’y connecte plus directement mais via Knox.
- Diminuer le nombre de services avec lesquels le client doit interagir car désormais il communiquera uniquement avec Knox.
- Simplifier le mécanisme d’authentification en n’en utilisant qu’un seul basé sur du HTTP, dans le cas où les clusters sont déjà sécurisés.
En terme de sécurité, Knox fonctionne avec les différentes couches d’autorisation et d’authentification des clusters Hadoop. Il est donc utilisable avec Apache Ranger, Kerberos , le protocole LDAP, … et s'intègre bien avec les principaux IMS (Identity Management Solutions) du marché .
LogSearch
Ambari Log Search vous permet de rechercher les journaux générés par les composants HDP gérés par Ambari. Ambari Log Search s'appuie sur le service Ambari Infra pour fournir des services d'indexation Apache Solr.
Deux composants composent la solution Log Search:
- Log Feeder
- Log Search Server

Log Feeder
Le composant Log Feeder analyse les journaux des composants. Un chargeur de journaux est déployé sur chaque noeud du cluster et interagit avec tous les journaux de composants sur cet hôte. Au démarrage, le Log Feeder commence à analyser tous les journaux de composants connus et les envoie aux instances Apache Solr (gérées par le service Ambari Infra) pour être indexés.
Par défaut, seuls les journaux FATAL, ERROR et WARN sont capturés par le chargeur de journaux. Vous pouvez ajouter temporairement ou définitivement d'autres niveaux de journal à l'aide des paramètres de filtre de l'interface utilisateur de recherche de journal (pour la capture de niveau de journal temporaire) ou via le contrôle de configuration de recherche de journal dans Ambari.
Log Search Server
Le serveur de recherche de journaux héberge l'application Web de l'interface utilisateur de recherche de journaux, fournissant l'API utilisée par Ambari et l'interface utilisateur de recherche de journaux pour accéder aux journaux des composants indexés. Après vous être connecté en tant qu'utilisateur local ou LDAP, vous pouvez utiliser l'interface utilisateur de recherche de journaux pour visualiser, explorer et rechercher les journaux des composants indexés.
NiFi
Apache NiFi est un projet open source de la fondation Apache, supporté par Hortonworks. Il permet d’injecter automatiquement des flux de données entre différents systèmes sources en direction d’autres systèmes en cible.
Par exemple, NiFi peut être très utile dans un cas d’usage comme l’alimentation d’un DataLake Hadoop à partir de plusieurs sources de données.
Basé sur le paradigme de programmation flow-based programming, NiFi fournit une interface web qui permet de construire un flux de données en Drag et Drop. Ainsi, il est possible de définir, de contrôler en temps réel, et d’une certaine manière, de sécuriser l’acheminement de données.
Apache NiFi assure l’intégralité du flux de données, il est tolérant aux pannes, est scalable et a été conçu pour gérer de gros volumes de données en temps réel.
Apache NiFi est compatible avec Kerberos qui assure l’authentification, avec Apache Ranger qui permet la sécurité des autorisations d’accès et avec Apache Knox qui gère la sécurité au niveau authentification et celle des appels REST and HTTP.
NiFi-Registry
Registry, un sous-projet d'Apache NiFi, est une application complémentaire qui fournit un emplacement central pour le stockage et la gestion des ressources partagées sur une ou plusieurs instances de NiFi et/ou MiNiFi.
Les objectifs spécifiques de l'orientation initiale de l'effort de registre comprennent:
- Implémentation d'un registre de flux pour stocker et gérer les flux versionnés
- Intégration avec NiFi pour permettre le stockage, la récupération et la mise à niveau des flux versionnés à partir d'un registre de flux
- Administration du registre pour définir les utilisateurs, les groupes et les politiques
Ranger
Apache Ranger permet une approche globale de la sécurité pour les clusters Hadoop. Il fournit une plateforme centralisée permettant de définir, administrer et gérer les politiques de sécurité de manière cohérente à travers l'écosystème Hadoop.
Apache Ranger propose un framework de sécurité centralisé permettant de gérer les contrôles d'accès détaillés dans les écosystèmes suivants :
- Apache Hadoop HDFS
- Apache Hive
- Apache HBase
- Apache Storm
- Apache Knox
- Apache Solr
- Apache Kafka
- Apache NiFi
- YARN
Grâce à la console Apache Ranger, les administrateurs de sécurité peuvent gérer facilement les politiques d'accès aux fichiers, dossiers, bases de données, tables ou même colonnes. Ces politiques peuvent s'appliquer à des utilisateurs individuels comme des groupes, et ce en permanence et sur toute la pile HDP.
Ranger KMS (Ranger Key Management Service) fournit un service de gestion de clés de chiffrement évolutif permettant de chiffrer les « données au repos » HDFS. Ranger KMS est basé sur l'Hadoop KMS développé à l'origine par la communauté Apache et vient compléter la fonction native d'Hadoop KMS en permettant aux administrateurs système de stocker des clés dans une base de données sécurisée.
Ranger offre également aux administrateurs de sécurité une vision approfondie de leur environnement Hadoop via une implantation d'audit centralisée qui contrôle toutes les demandes d'accès en temps réel et prend en charge de nombreuses sources de destination, notamment HDFS et Solr.

Storm
Storm est un système de calculs distribués créé par Nathan Marz et son équipe de chez BackType (plus tard racheté par Twitter) permettant le traitement en temps-réel de gros volumes de données soumises à des opérations de lectures/écritures aléatoires. Il permet de répondre à des problématiques Big Data liées aux traitements temps-réel.
La quintessence de Storm repose autour des caractéristiques suivantes :
- Rapidité: près d’un million de messages de 100 octets peuvent être traités par seconde par noeud
- Scalabilité: grâce au parallélisme des opérations à travers les noeuds du cluster.
- Fiabilité: chaque tuple sera traité au moins une fois ou une seule fois. Les messages ne sont rejoués qu’en cas d’échec.
- Tolérance aux pannes: en cas d’indisponibilité d’un noeud, le worker node associé sera redémarré sur un autre noeud.
- Facilité de prise-en-main: une fois déployé, Storm est facile à utiliser.
En outre, Storm supporte une variété de langages de programmation (C#, Java, Python,…) et apparaît comme la plateforme idoine pour traiter une variété de scénario tels que :
- Le monitoring d’applications.
- La détection de fraudes financières (banque, assurance,…).
- L’analyse comportementale d’utilisateurs (réseaux sociaux, e-commerce,…).
- …
Un cluster Storm est sensiblement comparable à un cluster Hadoop. Là où sur Hadoop, on exécute des jobs MapReduce, Storm utilise ce qu’on appelle des « topologies ». Au-delà de leur terminologie, c’est surtout au niveau de leur fonctionnement que les jobs et les topologies diffèrent. En effet, là où un job MapReduce peut se terminer, une topologie, quant à elle, tourne en continu.
Storm possède 2 types de noeuds:
- Un noeud maître (master node), qui exécute un démon appelé Nimbus, qui peut être comparé au JobTracker de Hadoop. Un tel noeud est responsable de la distribution d’instructions sur le cluster, de l’attribution de tâches, le monitoring…
- Des noeuds esclaves ou travailleurs (worker nodes), qui exécutent un démon appelé Supervisor. Le superviseur écoute les travaux confiés à son noeud et démarre ou arrête le processus de travail si nécessaire, en fonction des ordres de Nimbus. Chaque processus de travail exécute un sous-ensemble d’une topologie, sachant qu’une topologie en cours d’exécution se compose de nombreux processus de travail répartis sur de nombreuses machines.
Nimbus communique avec ses superviseurs via un coordonnateur appelé ZooKeeper. L’état de fonctionnement de chaque démon (Nimbus et superviseurs) est maintenu dans Zookeeper ou sur le disque local. De cette façon, en cas d’arrêt de Nimbus et des superviseurs, ceux-ci vont commencer à remonter comme si de rien n’était.

Storm possède principalement 5 niveaux d’abstraction lui permettant de traiter efficacement des données :
- Les tuples, qui sont des structures de données sous forme de listes d’éléments ordonnés en tant que collections de paires clé/valeur.
- Les flux (ou streams), qui sont, en fait, des séquences de tuples illimitées.
- Les spouts (becs, en français), qui sont des sources de flux qui peuvent lire des tuples et les émettre comme des flux. Exemple classique : connexion d’un spout à l’API de Twitter pour émettre un flux de tweets.
- Les bolts (boulons, en français), sont des « transformateurs » mono-étapes de flux. Ils créent de nouveaux flux en fonction des flux d’entrée. Lorsqu’une transformation nécessite plusieurs étapes, alors autant de bolts que d’étapes sont utilisés. Les types de transformation sont variées (filtrages, agrégations, jointures, tris,…).
- Les topologies, évoquées plus haut comme l’équivalent de jobs MapReduce au sein d’Hadoop. Il s’agit concrètement d’un réseau graphique où chaque noeud représente un spout ou un bolt. On parle également d’un réseau de flux d’abonnements, avec les spouts comme sources de données et les bolts comme abonnés, sachant qu’un bolt peut être la source de données d’un autre bolt.

Lorsqu’un spout ou un bolt émet un flux, il envoie le tuple à tout bolt qui souscrit à ce flux. Les spouts et bolts exécutent de nombreux threads sur le cluster Storm, et passent des messages les uns aux autres de manière distribuée. Le tout, sachant qu’il n’y a pas de files d’attente intermédiaires.
Pour finir, Storm offre également la possibilité de contrôler le routage des tuples vers des bolts au sein d’une topologie. Il s’agit de ce qu’on appelle le stream grouping (ou regroupement de flux), qui se décline en plusieurs types d’opérations personnalisables :
- Shuffle : envoi de tuples vers des bolts de façon aléatoire. Exemple d’usage : opérations mathématiques.
- All : envoi d’une copie de chaque tuple à tous les bolts. Exemple d’usage : envoi d’un signal à tous les bolts.
- Global : envoi d’un flux en entier (i.e., de l’ensemble des sources) vers un ou plusieurs bolts.
- Direct : envoi ciblé de tuples. En d’autres mots : les bolts destinés à recevoir les tuples sont, ici, spécifiquement choisis.
- Fields : envoi de tuples vers un bolt en fonction d’un ou plusieurs champs (fields) de tuples (on parle de flux partitionné). Exemple d’usage : comptage de tuples d’un type défini.
Streaming Analytics Manager (SAM)
Comme l'illustre le diagramme suivant, Hortonworks Streaming Analytics Manager (SAM) est une application de la suite de traitement de flux de la plate-forme HDF:

Utilisez Streaming Analytics Manager pour concevoir, développer, déployer et gérer des applications d'analyse de streaming avec un paradigme de visualisation par glisser-déposer. Streaming Analytics Manager vous permet de créer des applications d'analyse en continu pour la corrélation d'événements, l'enrichissement du contexte, la correspondance de modèles complexes et les agrégations analytiques. Vous pouvez créer des alertes et des notifications lorsque des informations sont découvertes.
Streaming Analytics Manager est indépendant du moteur de streaming sous-jacent et peut prendre en charge plusieurs substrats de streaming tels que Storm, Spark Streaming, Flink, etc. Le premier moteur de streaming entièrement pris en charge est Apache Storm.